この右手法を使うことで、仮に時間はかかったとしても、必ず出口にたどり着くことができます。
とはいえ、出口にたどり着くまでに100年もかかったのでは意味がありませんよね。より短時間で解くことができる探索アルゴリズムの開発が重要です。
現在、膨大なデータの中から高速にデータを見つけ出す探索アルゴリズムの典型例としては、まず、「二分探索」が挙げられます。
通常、紙の辞書はあいうえお順やアルファベット順に並んでいますよね。マークがついている辞書も多いですが、もし今、自分が使っている辞書にマークがついていないとして、調べたい単語を効率的に見つけ出すには、どうすればよいでしょうか。
分厚い辞書で「タコ」を調べる方法
たとえば、「タコ」という単語を調べたいとします。このとき、辞書のちょうど中央辺りを開くのです。そして、開いたページの最初の単語を見ます。その単語が仮に「ハト」だった場合、「タコ」は必ず2つに分けた前半のページにあるはずです。
そこで次に、前半のページの中央辺りを開きます。そして、開いたページの最初の単語を見ます。その単語が仮に「サル」だった場合、「タコ」は必ず2つに分けた後半のページにあるはずです。
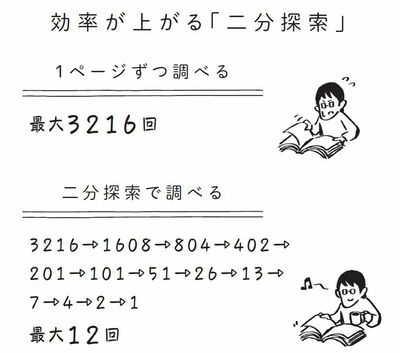
これを繰り返していくことで、どんどんページの範囲が狭められていき、その結果、「タコ」が掲載されているページにたどり着くことができるのです。
辞書の中でも非常に分厚い『広辞苑』でも、この操作を最大12回繰り返すだけで、掲載されているページにたどり着くことができます。これが、二分探索と呼ばれる方法です。
ここでは、単語があいうえお順やアルファベット順に並んでいるということが重要です。このような性質を「単調性」といいます。
この二分探索というアルゴリズムは、インターネット上のさまざまな探索(検索)に使われています。たとえば、あなたがパソコンやスマホを開き、Facebookにログインするとします。このとき、Facebookはまず、あなたのアカウントを確認します。














