おりしも当時、私は別の理由で統計とプログラミングを学び始めていた。言語の数量的な側面を分析するためには、どうしても、この2つの技術が不可欠だと悟ったのである。そして、「日本語ラップで組み合わされる子音には音声学的に似たものが多い」ことを統計的に証明することが自分の使命であると、当時の私は感じていた。
これで理論的な素地も、技術的な素地も整った。大学院生だった私は、上記の命題を統計的に検討するために、1日1曲、自分の好きな曲の韻をテキストファイルに落とし込むことを自分に課した。同時に、そのテキストファイルから子音のペアを抽出し、それぞれのペアの数を数え上げるプログラムも用意した。そして、100曲そろったと思ったその日、分析を開始したのである(痛恨のミスで、曲数を間違えており、実際は98曲だったのはご愛敬)。
ついに日本語ラッパーたちの優秀さを示した
このオタク的努力の結果、私は、「日本語ラップで組み合わされる子音には音声学的に似たものが多い」という命題を統計的に示すことに成功した。
まず、韻における組み合わされやすさの尺度として、観測値を期待値で相対化したものを計算。それだけでは、分布がかたよっていたので対数変換を施した。ちょっと難しい表現だが、これは「2つのものの組み合わされやすさ」を統計的に計測するためによく使われていた尺度だ。
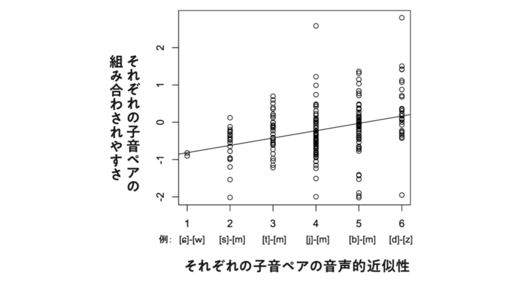
「音声学的にどれだけ似ているか」という尺度には、「調音点(=口のどこで発音するか)」「調音法(=どうやって発音するか)」「有声性(=声帯は振動するかどうか)」など音声学で使われる尺度を用いた。この分析の結果、図に示すように、「韻における組み合わされやすさ」(縦軸)と「音声学的にどれだけ似ているか」(横軸)という2つの尺度に統計的な相関があることを見出した。
それだけでなく、重回帰という手法を用いて、どの音声的な特徴がどれだけ韻の踏まれやすさに影響を与えるかまで考察した。そしてこの考察をもって「日本語ラッパーたちは、適当に子音を選んでいるわけではなく、音声学的にも理にかなった方法で韻を踏んでいる。彼らは言語学的感性に優れた人々なのだ」と結論づけたのである。