ここで問題になってくるのは、表1に挙げている「価値観」の数値に、明確な分類基準がないことである。性別で分けるなら男性と女性、年齢で分けるなら10歳区切り、また居住地域で分けるなら都道府県別など、はっきりとした区切りがある。
しかし何項目もある価値観の数値を基にグループを作ろうと考えた場合、「健康志向」は何ポイント以上なら強い、「節約志向」は何ポイント未満なら弱い、と決められるような基準がないのである。
今回紹介するのは、そうした分類基準が明確ではない指標を基に、似た傾向の人同士を集めることでデータのグループ化を行うことができるクラスター分析という分析手法である。
顧客像を把握するためによく使われるクラスター分析
クラスター分析とは、集団(データ)をいくつかの「クラスター」というグループに分類する手法である。因子分析が変数(例:アンケート項目)をまとめる分析手法だったのに対して、クラスター分析は人や店舗などのデータ単位をまとめる分析手法だ。
マーケティングにおいては顧客像把握のために頻繁に使われる手法の1つであり、表1で例に挙げたアンケートデータだけでなく、購買履歴やスマートフォンの利用ログなど、さまざまなデータに対して行うことができる。「クラスター」とは(果物の)房、塊、群れ、集団などの意味を持つ単語で、似たような属性や共通点を持つヒトやモノなどの集団を指す。
なお、新型コロナ関連の報道で見聞きするようになった「クラスター分析」とは異なるので要注意だ。そちらは「クラスター=感染者群」と捉え、その発生メカニズムを調べる分析を指す。
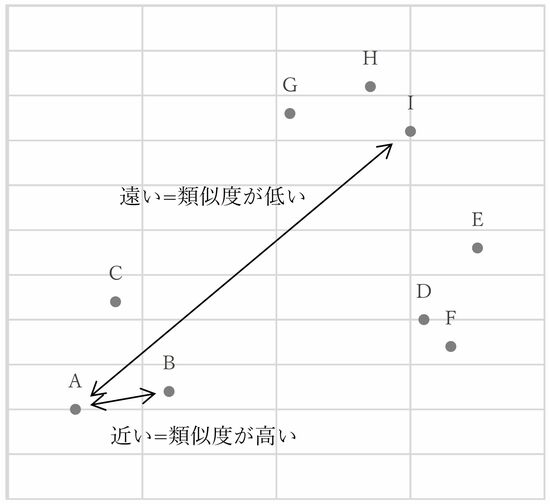
クラスター分析の考え方は、各データ同士の「類似度」に基づいて、似ている=近い傾向のデータを同じクラスターに分類し、似ていない=遠い傾向のデータは別のクラスターと判定するというものである。
図1の例で見ると、点Aと点Bは距離が近い=類似度が高いが、点Aと点Iは距離が遠い=類似度が低いと考える。図1のように直線距離で測る距離をユークリッド距離と呼び、一般的な距離の測り方の1つである。ほかにもマンハッタン距離、マハラビノス距離などの測り方がある。
●図1:ユークリッド距離で測る例