各委員の講演テキストにはそれぞれの考えや主張が反映されているのであれば、それを機械学習することによってさまざまな文章がどの委員の発言に近いかを分類する「分類器」を作ることができる。
具体的には、各政策委員の講演テキストをセンテンスごとに切り分け、それぞれのセンテンスが誰の発言であるかを学習する(今回は全体で2974センテンスが分析対象となった)。どのセンテンスが誰の発言であるかをセットで学習する(ラベル付けするとも言う)ことになるので、機械学習における「教師あり学習」を実行することになる。
「分類器」の精度を求めるため、各委員の講演テキストに含まれるセンテンスのうちの一定数(全体の80%)をランダムに抽出し、それを学習データとして残りのデータ(が誰の発言か)を正しく予想できるかという検証を複数回行った。なお、分類器の設定については、Random ForestとNeural Networkをそれぞれ用いて検証したが、今回は前者の正答率が全体に高かったため、以下ではすべてRandom Forestを用いた結果を示す。
正答率は52%、テキストがそろえば62%も可能
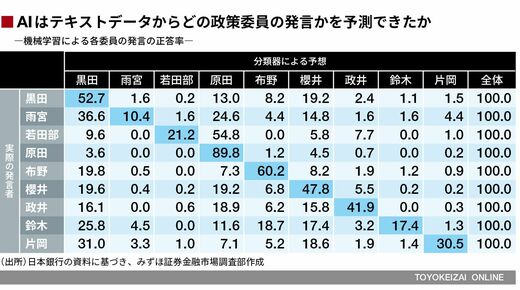
委員は9人いることを考えると、ランダムに予想すれば正答率は約11.1%(=9分の1)となるが、検証の結果、機械学習による各委員の発言の正答率は約52%まで向上した。機械学習によって、どの政策委員の発言内容かを予測できる精度を高めることは、可能であることがわかる。
なお、どの委員の発言が「予測しやすいか」を調べるため、テキストデータのうちランダムに選んだ80%を学習データ、残りの20%を検証データとして正答率を求めた。
原田審議委員(正答率89.8%)の発言の分類は比較的容易であることがわかったが、これは、前述のように、原田審議委員は全体の総意とは違った発言が目立つためだと思われる。一方、雨宮副総裁の正答率は低くなったが、これは講演テキストの不足によって学習データに限りがあったことが原因であると考えられる。
ほかにも、講演テキストが少ない若田部副総裁も正答率が低く、同じリフレ派とされる原田審議委員と分類されてしまう比率が高かった。そこで、テキストの少ない雨宮副総裁と若田部副総裁、鈴木審議委員、片岡審議委員を分析対象から外して同じ検証を行ったところ、各委員の発言の正答率は約62%まで向上した。
今後も講演テキストを蓄積し、精度の向上を図る必要があるものの、今回作成した「分類器」はある程度の正答率を発揮しているとみられる。
総じてAI・機械学習は「BOJウォッチ」をある程度上手にこなすことができ、市場の「BOJウォッチャー」の脅威となる可能性もあるだろう。














