1/4 PAGES
2/4 PAGES
3/4 PAGES
テキストマイニングの1つの手法として、複数の文章の「類似度」を測る方法がある。具体的には、文章に使われている単語(名詞)の種類と使用頻度をBoW(Bag of Words)と呼ばれるベクトル(行列)で表現し、2つの文章ベクトルのcos類似度(コサイン類似度、内積)を求める。
まったく同じベクトルであれば1、無関係であれば0となる。つまり、2つの文章をそれぞれベクトルで表現したときに、同じような方向を向いていればcos類似度は大きくなり、2つの文章は「似ている」ことになる。
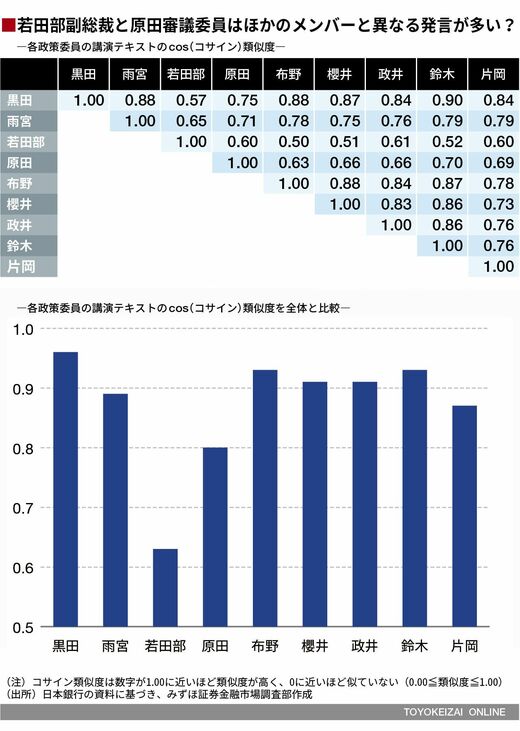
9人の講演テキストについて、それぞれの「類似度」を求めた結果を表にしてみた。また、各委員の講演テキストと9人全員のすべての講演テキストを1つにまとめたテキストデータとの「類似度」を求めてグラフにしてみると、全体の総意を述べることが多い黒田東彦総裁は全体との類似度が高いことがわかる。
原田審議委員は全体の総意と「類似度」が低い
一方で若田部副総裁や原田審議委員は全体との類似度が低い。若田部副総裁の場合は分析に用いたテキストの量が少ないことから割り引いて見る必要があるが、原田審議委員は全体とは異なる意見を述べることが多いといえそうだ。
「類似度分析」はそれぞれの委員の主張の距離感を測るために有用だろう。
4/4 PAGES














