例えば、イメージネット・チャレンジという世界的な画像認識コンテストでは、画像に写っている物体が何かを予測して競い合う。画像の中の物体を予測するタスクは、人間にとっても難しい。イメージネットのデータは1000種類ものカテゴリーに分かれ、その中には犬種をはじめよく似た画像も含まれている。チベタン・マスティフとバーニーズ・マウンテン・ドッグ、あるいは金庫のダイヤルとダイヤル錠は、識別が困難だ。人間は全体のおよそ5%で間違いを犯す。
コンテストが始まった2010年から最後に開催された2017年の間に、予測は大きく改善された。次の図にはコンテストに優勝したチームの予測の正確さを年ごとに表した。
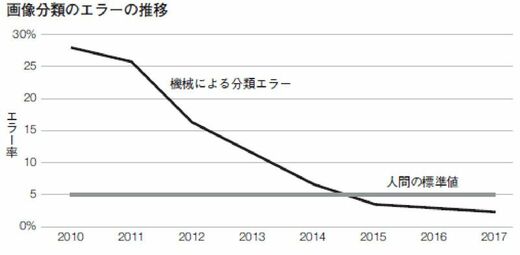
縦軸はエラー率なので、低いほど優れていることになる。2010年、最も成績のよかった機械による予測は、エラー率が27%だった。2012年にコンテスト参加者がディープラーニングをはじめて使うようになると、エラー率は16%にまで下がった。
ついにエラー率は人間の標準値の半分以下に
プリンストン大学教授でコンピューター科学者のオルガ・ルッサコフスキーは、次のように語っている。「2012年には、正確さに関して大きなブレークスルーが実現した。しかしそれは、数十年前から存在してきたディープラーニングという概念の正しさの証でもあった」。
アルゴリズムの著しい改善はその後も続き、2015年には、あるチームのエラー率が人間の標準値をはじめて下回った。2017年になると、参加した38チームの大半が人間の標準値を下回り、優勝チームのエラー率は人間の標準値の半分以下になった。機械はこのようなタイプの画像を人間よりも上手に確認できるようになったのである。
もうひとつ、近年AIが達成した大きな成果が、言語翻訳だ。グーグルの翻訳サービスの質がいきなり向上した結果、翻訳は魔法のように感じられる。
例えば、アーネスト・ヘミングウェイの「キリマンジャロの雪」は、次のような美しい文章で始まっている。













