機械学習では、学習データと呼ばれるものをもとに、機械(コンピューター)が自動的に学習を行います。学習の回数を多くしたり、説明する要素を増やすことで、予測などの精度を高めることができます。しかし、学習データにだけ適応した学習だけが過剰に進んでしまうことがあります。
その結果、将来のデータ(説明変数)に対して、結果(目的変数)を推定する性能が下がってしまうことがあります。過去のデータのみを使って過剰に学習してしまうと、将来予測として使い物にならないのです。この状態を過学習と言います。
過学習を避けるためにはいくつかの方法があります。説明する側の式の複雑さが増すことに罰則をつけて学習させる「正則化」が代表的です。また、「ホールドアウト検証」という方法は、元データを学習用のデータと、検証用のテストデータに分けて学習結果を評価する方法です。学習用データで誤差を少なくすれば良いのではなく、テストデータにおける誤差も少なくするような学習結果を採用する考え方です。
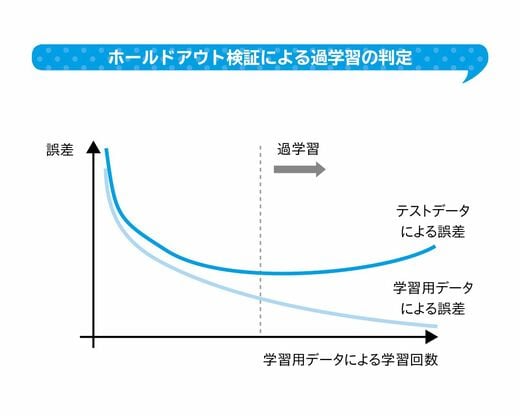
このようにデータサイエンティストの業務内容は、ビジネスに直結するようになってきていますが、その一方で、課題も多くあります。たとえばこの過学習のように、専門的な知識がないと、誤った結論を出してしまうこともあります。そのために、データサイエンティストとしての能力を「資格」という形で証明することも求められてきているのです。
データサイエンティストの業務と資格
データサイエンティストが取得している、あるいは、これから取得しようとしている資格には以下のようなものがあります。
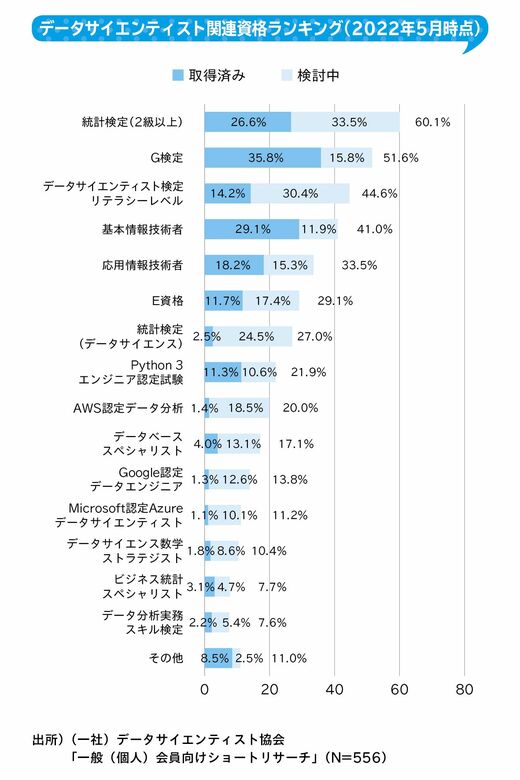
データサイエンティスト協会は、データサイエンティストとして働いている人を対象に、持っている資格と、これから取得したい資格についてのアンケート調査結果を発表しました。

持っている資格の1位は、AI・ディープラーニングに関する知識やリテラシーが問われる「G検定」でした。G検定の「G」は「ジェネラリストGeneralist」を意味しています。2位はIT技術者の国家資格である「基本情報技術者」です。この資格試験にはIT技術者としての基本的な知識に加えて、アルゴリズムや情報セキュリティを問う設問もあります。
一方、これから取得したい資格については、「統計検定(2級以上)」が1位となりました。統計検定2級では、データをもとにした仮説の構築と検証といった統計学の知識が求められるため、データサイエンティストの登竜門とも言える資格となっています。
2位には、2021年にデータサイエンティスト協会が創設した、「データサイエンティスト検定(リテラシーレベル)」が続きます。これはデータサイエンティストに必要な3つの能力(データサイエンス力、データエンジニアリング力、ビジネス力)がバランス良く問われるもので、今までになかった切り口の資格と言えるでしょう。














