1/4 PAGES
2/4 PAGES
3/4 PAGES
この記事を執筆するに際して、ネット上で公開されている様々な「入試問題をAIに解かせてみた」という記事を拝見しましたが、文字認識の時点で齟齬が生まれておりAIの本領を発揮していないケースが多いように思われます。
実際、同様の条件で試した場合でも、文字認識を一度経由してから問題を解かせることで、正答率が向上することを確認済みです。
2026年1月現在のAIを教育の現場で活用しようと考えるのであれば、苦手な文字認識を人間がサポートしたのち、得意分野である科学的推論をAIに依頼することが大事であると言えるでしょう。
AIの性能は年々上がっている
AIの性能は年々、上昇し続けています。特にGPT-5.2のThinkingモデルは、コーディングや数学などのSTEM分野の推論だけでなく、専門知識を有しての知的労働を得意としExcelやPowerPointなどの外部ツールとの連携が可能であることをウリとしています。
ここではFrontierMathと呼ばれる、数学問題集を用いたAIベンチマーク測定用の結果を見てみましょう。GPT-5.2は、比較的簡単な問題群(大学院レベル)であるTier1~3で40.6%を、研究者向けの超高難易度問題群であるTier4では最大29.2%を獲得しており、これは他のAIモデルの中でトップスコアです。
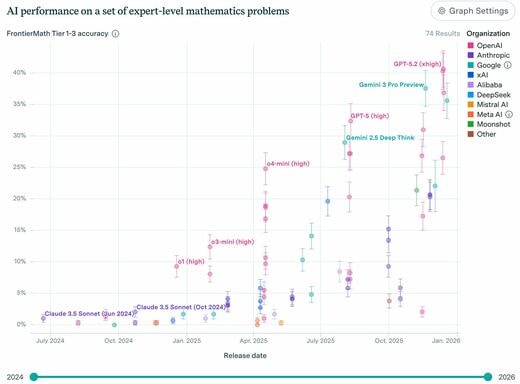
FrontierMathの作成元であるEPOCH AIが公表するベンチマーク比較。新しいモデルほど、正答率が高い(画像:筆者提供)
この比較表を見るだけでも、新しいモデル(右)ほど、正答率が高い(上)ことが分かります。
4/4 PAGES