ご存じのように、ChatGPT、Claude、GeminiなどのAIでは、個人情報はサーバー側で処理する。
もちろん、『個人情報をサーバー側で扱う=危険』というわけではない。ChatGPTの有料プランでは学習利用をオフにすることはできるし、企業向けプランでは顧客データをモデル学習には使わない。また、一部のサービスではデータを匿名化して統計利用している。
しかし、そもそもは個人情報を学習させたほうが、パーソナライズが進んで便利になるから、多くの人が個人情報を学習させていることだろう。言わば「便利さ」と「プライバシー」のトレードオフである。
また、当然のことながら広告ビジネスが主力であるGoogleのGeminiでは、興味関心の推定、広告表示の最適化、利用者分析にAIに入力した個人情報が使われる可能性がある。現時点でGoogleは「Geminiの会話内容を広告表示に直接使っていない」としているが、将来的には利用する可能性を「排除しない」としている。現在のChromeで検索したものが広告に表示されるのよりさらに高度に『パーソナライズされた』広告が表示されるというわけだ。これはGoogleがユーザーから直接お金を得ず、広告ビジネスで成立している会社である限りは当然のことだとも言える。
アップルが目指した『個人情報を担保したAI』の複雑な仕組み
逆にアップルは『個人情報を取得しない』ということをモットーにしているからこそ、ここまでAI機能の提供が遅れたともいえる。
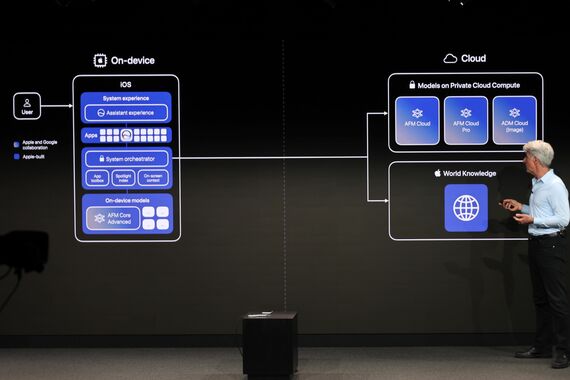
WWDC 26でアップルが発表した、Siri AIと、その基盤となるApple Intelligenceは、完全に個人情報を守りながら、連絡先、スケジュール、ドキュメントなどの個人情報を活用できるAIになっている。
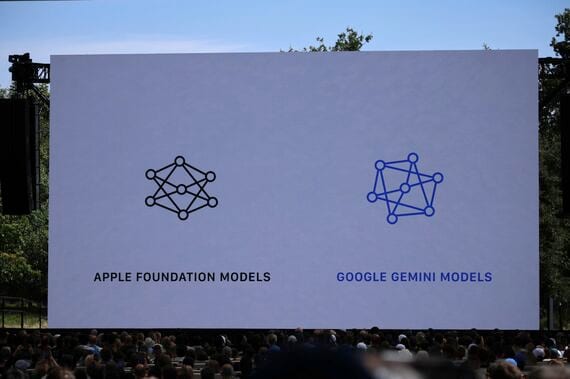
今回、アップルはGoogleのGeminiのモデルを活用してApple Foundation Models(AFM)を構築したが、ここにGoogleが自社顧客に提供しているGeminiアプリ、既存のインフラ、あるいはGoogle検索などのデータが含まれているわけではない。モデルの構築にはアップル独自のデータ(Proprietary data)が使われている。GoogleのGeminiテクノロジーは、あくまでモデルの品質をリファインするための技術協力として活用されている。
今回、アップルが発表したシステムの中にはいくつかのAIモデルがあり、それを『システムオーケストレーター』がハンドリングする。
システムオーケストレーターは、アップルのAIの中の『指揮者』のような存在だ。あなたの過去のデータや、今動いているアプリから渡されたデータ、ディスプレイに表示されているデータを統合して、必要に応じて用意されたAIモデルのいくつかに渡し、得られた結果をアプリに戻し、表示する仕組みになっている。