
さらにスキャンで発見された脆弱性のうちミュトスが「深刻度が高い」と推定した1752件に対して、6つのセキュリティ調査会社とアンソロピックでトリアージを行い、1587件(90.6%)が有効な真陽性、1094件(62.4%)が高またはクリティカルな深刻度であることが確認された。
また、発見された脆弱性は開発元に報告されパッチ(修正プログラム)の設計が行われるが、ミュトス限定公開版が発見した深刻度の高い、または重大なバグの修正には、平均して2週間かかるとしている。
Project Glasswingは当初、約50社の初期パートナーで進められていたが、6月2日に15カ国、約150社に拡大すると発表され、ミュトス級AIモデルが普及する前に先行して脆弱性対応を完了させることが期待されている。
ミュトス級の“組み合わせ”でより攻撃能力が高まる
ミュトス級AIモデルのエクスプロイト(脆弱性を悪用した侵入)能力を計測するベンチマークの開発も進んでおり、主要なベンチマークの1つにExploitGym(エクスプロイト・ジム)がある。
これは脆弱性の再現能力を評価するために作られていた「CyberGym」という既存のベンチマークの後継プロジェクトとしてUCバークレーなど複数の大学・研究機関が開発し、アンソロピック、OpenAI、Googleのセキュリティ研究者が貢献したものである。
下図はExploitGymを用いてミュトス限定公開版とGPT-5.5、その他の評価結果と解決した目標の重複を可視化したものである。
重複のない円はそのAIモデルのみが達成した目標達成数を示しており、ミュトス限定公開版は56件、GPT-5.5が26件と、このベンチマークでもミュトスの能力の高さが示されている。そして、円が重なっている部分は重複を示しており、両者が共通して目標達成に至った件数は91件(47+44)あった。
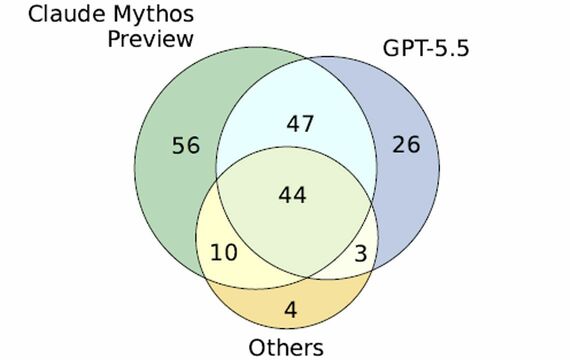
この重複した部分と単独のAIモデルのみが達成可能な目標があったという結果から、AIモデルが各々質的に異なるエクスプロイト戦略や推論パターンを保持していることを示唆する結果となった。













