
3万人のデータからテーマパークの利用者数を予測する
MRAとMRIが2011年から提供している「生活者市場予測システム(略称mif:ミフ)」は、全国の3万人(20~69歳)が2000項目以上のアンケートに回答している大規模なインターネットアンケートパネルです。3万人や2000項目以上という規模の大きさに加えて、10年以上の定点調査によって時系列のアンケートデータが取れる点も大きな強みとなっています。mifのデータを使ってMRAやMRIがさまざまな社会調査を行うことはもちろん、データは社外会員(民間企業や大学等)にも提供されているので、ユーザーがmifのデータを利用してマーケティング調査などを行うこともできます。
今回ご紹介するのは、mifのデータを使ってMRAが分析した「テーマパークの利用者数予測」です。全国各地にさまざまなテーマパークがありますが、人口減少や余暇の多様化の中で新たな顧客体験価値の創造が既存のテーマパークの重要な課題として挙げられています。では、テーマパークの利用者数を増やすには、どんな施策を打てばよいのでしょうか。
例えば、一度来園した人が再び何度も訪れてくれる、つまり「ヘビーユーザー」を増やすことができれば、利用者数の増加につながります。mifの中には、過去1年間にどのテーマパークに何回行ったかというアンケート項目があるので、このデータを分析しました。
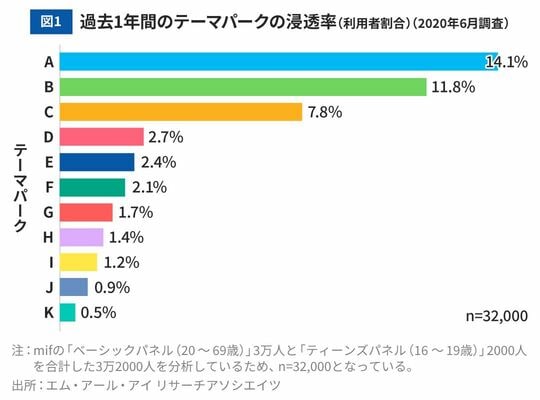
図1は、過去1年間に日本国内の主なテーマパークをそれぞれ1回以上利用した人の割合を示したもの(2020年6月調査)で、その割合を「浸透率(または利用者割合)」といいます。テーマパークごとに浸透率は異なり、最も浸透率の高いテーマパークAは14.1%、つまり約7人に1人が過去1年間でAを1回以上利用していることがわかります。Aのように浸透率が高い、つまり人気の高いテーマパークもあれば、浸透率が200人に1人(0.5%)程度のテーマパークもあります。
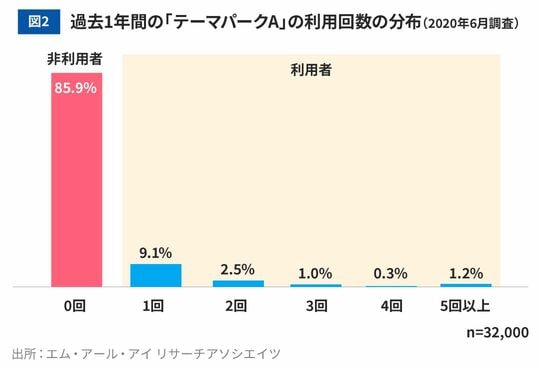
次に、最も浸透率が高いテーマパークAについて、年に何回利用したかを分析したものが図2です。これを見ると、1年間に5回以上訪れるようなヘビーユーザーの割合は全体の約1.2%だとわかります。実際の人数は380人でした。一般に、出現率が低い人々の行動を詳しく分析するためには、より多くのサンプルサイズを確保する必要があります。mifは3万人(以上)の大規模アンケートパネルであるため、全体の1%程度という出現率の低い事象であっても380人という十分なサンプルサイズを確保できており、mifの強みが発揮されているケースとなっています。なお、図2で示される利用回数の分布はマーケティング分野によく現れる「負の二項分布」で近似できることがわかっています。
ヘビーユーザーの割合とテーマパークの人気との関係
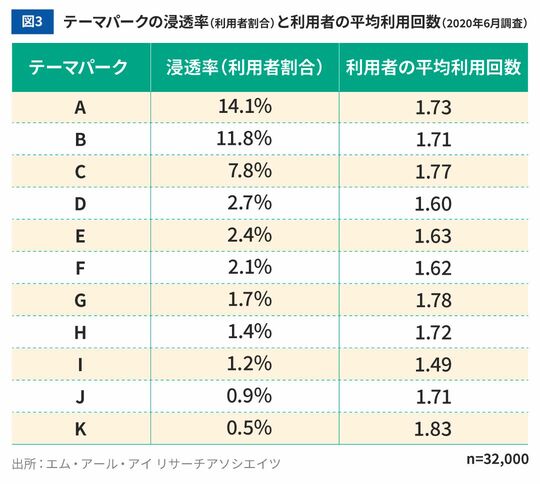
では、ヘビーユーザーの割合はテーマパークごとに異なるのでしょうか。図3は、テーマパークの浸透率と、「利用者の平均利用回数」の表です。利用者の平均利用回数とは、そのテーマパークを1回以上利用した人たち(つまり非利用者を除いた人たち)が、年に何回利用したのかを平均した値であり、この値が大きいほど複数回訪れた人やヘビーユーザーの割合が高いといえます。
図3のとおり、利用者の平均利用回数は浸透率にかかわらず、どのテーマパークもおおむね1.6~1.8回となっています。つまり、多くの人が来園するテーマパークも、そうではないところも、複数回来園する人の割合に大差はないことがこの分析からわかるのです。
洗剤やシャンプーなどの生活必需品のブランドでは、浸透率が上がるほど購入者の購買頻度も上がることが知られていて、「ダブルジョパディ(二重苦)の法則」と呼ばれます。人気がある商品ほどヘビーユーザーが多くてどんどん買われ、逆に人気がない商品は購入頻度も少ないのでますます売れない、ということです。しかしこの法則は、テーマパークにはどうやら当てはまらないことが分析によって明らかになりました。
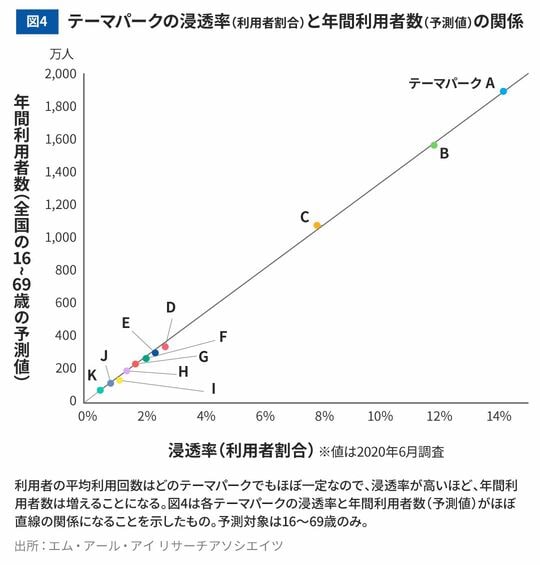
このことから、「利用者の平均利用回数」はどのテーマパークでもほぼ一定なので、利用者の総数(総入場者数)を増やしたければ浸透率を上げる、すなわち1回でも来園してくれる人を増やすべきであることになります。そして浸透率の予測は利用意向としてアンケートで把握できるので、この関係を用いてテーマパークの利用者数予測が可能です(図4)。また、同じような傾向はテーマパークに限らず商業施設や文化施設などでも見られることがわかっており、その応用範囲は広いと考えています。
新型コロナウイルスの感染シミュレーション
続いて、社会のモデル化によって将来のシナリオを示した研究について紹介しましょう。それは新型コロナウイルス「COVID-19」の感染シミュレーションです。2020年3月から4月ごろ、新型コロナウイルスの第1波の時期に、このプロジェクトはスタートしました。その背景には、MRAは技術に特化したシンクタンクであり、社会に新たな問題が発生した際には、原理に基づいた解析によって有効な対策を検討・提言しなければならないというMRAの信念がありました。同時にMRIでも新型コロナウイルスに対する提言活動が行われつつあることが明らかになり、グループ全体で1つの方向性を定めて取り組むことになったのです。
当時の日本では「SIRモデル」と呼ばれる、日本全域の感染者情報を基に方程式を解くシンプルでスピーディーな分析が注目されていました。しかしSIRモデルでは、人々のどのような行動が感染の拡大に影響し、どのように振る舞えば感染が減るのか、そのミクロなメカニズムを明らかにすることはできません。そこでMRAは「マルチエージェントシミュレーション」に基づく感染シミュレーションの手法を開発し、東京都内における個人の行動と感染リスクの関連性を分析しました。マルチエージェントシミュレーションでは、さまざまな属性を持ち自律的に行動する多数の主体(エージェント)が仮想社会を構成することで、人々の行動に基づく社会現象の分析が可能となります。人々の行動のモデル化には、MRI協力のもとスマートフォンから得られるGPS位置情報を人流として活用しました。
シミュレーションの結果、2020年の第1波で感染が拡大し、収束するまでの一連のGPS位置情報から、感染リスクの高い場所の特定や感染を収束させた要因を明らかにしました。東京都内においては、平日の日中にオフィス街のサービス業(小売店や飲食店など)で人々の接触率、すなわち感染リスクが高く、また、夜間や休日には異なる地域で感染が発生していることがわかりました(図5)。
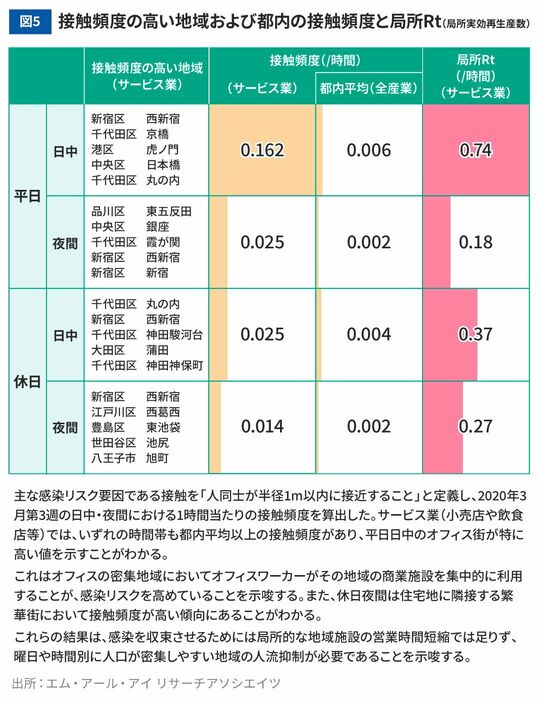
さらに、シミュレーションに対して「いつ・どこで・誰が・誰に感染させられたか」を追跡できる機能を追加し、結果に対するネットワーク分析を行い、国内における新型コロナウイルスの感染の連鎖現象を可視化しました(図6)。

{kind=link}
人と人との接触による感染拡大や、狭い飲食店などでの大声の会話による感染などは、多くの人が定性的・感覚的にわかっていたものですが、具体的な危険性が定量的にはわからないまま過ごされていたものと思われます。これに対して私たちのシミュレーションでは、モデルを作って計算を行うことで、感染の拡大や収束をシナリオ分析に基づく予測から数字できちんと示すことができたことになります。このような取り組みは施策の妥当性を示すのみならず、問題の解決に向けどのような行動が効果的なのかを明らかにすることができます。近年重要視されているEBPM(エビデンス・ベースト・ポリシー・メイキング:証拠に基づく政策立案)の観点からも、こうした取り組みは非常に大事であると考えています。
MRAの将来展望:数値解析の力でよりよい未来を目指す
データとその解析に基づく実態把握や予測はますます重要になってきます。その際、単に独自のデータを持っている、数値解析ができるというだけでなく、それを組み合わせることで新たな課題解決が期待されます。今後MRAは、例えばmifのデータをマルチエージェントシミュレーションの中で活用するなど、数値解析スキルと組み合わせることで、個人の行動や意識をより精度よく予測する取り組みにもチャレンジしたいと考えています。また、mifをより多くのユーザーに利用してもらうために、生成AIを使って自動でアンケートデータを分析する仕組みの研究開発も行っています。
先ほど触れたEBPM実現へ向けての取り組みも重要です。最近はEBPMの「一歩先」の考えとして、精度のよいシミュレーションによって結果を予想し、将来生じうるさまざまなシナリオにおける分析結果を基に政策立案を行おうとする動きも進んでいます。そうした際に、数字の根拠をしっかりと出すことで最善の選択のうえで世の中を動かし、課題解決を進めていく力の一助になることが重要であると考え、そこに取り組んでいきたいと考えています。
グループの一員としてリサーチや数値解析を行うMRA
最後に、MRAの会社概要をご紹介します。MRAは 1984年、MRIのソフトウェア開発、情報技術開発を担当する目的で設立されました。その後、2006年にITソリューション事業をダイヤモンドコンピューターサービス(DCS)に事業統合し、社名をMRAに変更してMRIグループ内でのリサーチ事業を担う新たな会社に生まれ変わりました。
現在の業務内容は「リサーチ・コンサルティングサービス」「PMO(プロジェクト・マネジメント・オフィス)支援サービス」「数値解析サービス」の3つに大別され、MRIのコア事業であるシンクタンク・コンサルティング事業のパートナー会社として、事業を推進しております。今回メインで紹介したものは数値解析サービスで、解析・数値シミュレーションの専門家を多く擁し、インフラや環境、まちづくり・防災、産業・労働、介護・福祉等の社会科学分野や、地震、津波、気候変動といった自然科学分野において、分析やシミュレーションを行っています。さらにリサーチ・コンサルティング部門が持つ、社会課題に対する深い知識や政策ニーズの知見を基にして解析・分析ができるという強みも有しています。これらによって、多くの顧客の課題やさまざまな社会課題の解決に貢献しています。

エム・アール・アイ リサーチアソシエイツ データサイエンス事業部 部長
東京大学大学院理学系研究科地球惑星科学専攻修士課程修了後、2007年にエム・アール・アイ リサーチアソシエイツ入社。環境・エネルギー分野の調査研究に関わり、アンケート調査の設計・分析にも従事。2020年より生活者市場予測システム(mif)の事務局を担当、機械学習や生成AIを用いた新たなmifアンケートデータ活用方法の開発も担当。

エム・アール・アイ リサーチアソシエイツ 数理システム事業部 広域社会解析チーム チームリーダー 博士(工学)
慶應義塾大学大学院理工学研究科後期博士課程修了後、東京大学物性研究所特任研究員を経て、2020年にエム・アール・アイ リサーチアソシエイツ入社。スーパーコンピューターやビッグデータを活用した大規模数値計算、社会シミュレーションに基づく政策検討や意思決定支援等に従事。2023年より、社会シミュレーションと計量経済を組み合わせスープラの予測・評価を行うチームを設立。
●関連ページ
大規模アンケートデータ×分析手法の紹介
第1回 3万人データの確率分布分析:テーマパークの利用者数予測モデル
新型コロナウイルス感染シミュレーション